“Nos trinques” - Tidy data e o pacote tidyr
04/05/2020
O que é “tidy data”?
Pra quem está acostumado a trabalhar com os microdados do IBGE ou do Ministério da Saúde, a ideia de um dado “organizado” pode parecer bastante óbvia. Em suma, um dado “tidy” é um dado em que cada linha representa uma observação. No caso dos demógrafos, as observações geralmente representam pessoas numa população humana. Ou seja, cada linha representa uma pessoa e cada coluna representa uma informação que temos sobre ela. Claro que é possível fazer uma definição mais genérica que isso, mas essa nos é suficiente por enquanto.
O pacote tidyr
Este pacote também faz parte do “tidyverse”, conjunto de pacotes que introduzimos lá atrás no ggplot2, depois no dplyr, e seu objetivo é transformar dados “não-tidy” em dados “tidy”, o que ele faz através de quatro funções: pivot_longer(), pivot_wider(), unite() e separate().
Vamos tentar demonstrar a utilidade dessas funções mesmo num contexto em que não precisamos reorganizar nossos bancos de dados. O fato é que frequentemente essa reorganização é importante para realizar etapas de métodos demográficos ou produzir gráficos.
O banco de dados da PNAD de 2015
Última PNAD anual antes de sua substituição pela PNAD Contínua, é um banco de fácil obtenção e também fácilmente carregado em R. Ele pode ser baixado diretamente do site do ibge, mas para facilitar as coisas, os arquivos foram subidos no Classroom.
O código abaixo é um extrato de apenas algumas variáveis, que utilizaremos para tentar construir uma pirâmide etária.
library(readr)
colunas <- fwf_cols(
ano = c(1, 4),
uf = c(5, 6),
sexo = 18,
idade = c(27, 29),
peso = c(791, 795)
)
tipos <- cols(
ano = col_character(),
uf = col_character(),
sexo = col_character(),
idade = col_integer(),
peso = col_double()
)
pnad <- read_fwf(
file = "_pnad2015/Dados/PES2015.gz",
col_positions = colunas,
col_types = tipos
)
pnad$sexo <- factor(pnad$sexo, labels = c("Masculino", "Feminino"))
pnadAs funções do pacote tidyr
unite() e separate()
unite() e seu contrário, separate() são responsáveis por juntar/separar os dados de uma coluna/variável. Um dos melhores exemplos seria a leitura do Censo, em que você tem uma estrutura mais ou menos assim:
Eu poderia querer reunir essas variáveis em uma só, chamada “muniat”. Preciso de uma função que “cole” o valor de cada célula uma na outra. Logo:
Normalmente, unite() apaga as colunas originais depois de juntar, mas eu especifiquei remove = FALSE para evitar isso. Unite funciona como outros pacotes do tidyverse, você especifica um banco de dados, dá um nome pra sua coluna nova e depois específica quais colunas serão “coladas” e qual separador você quer entre elas. Ali, eu disse que não queria separador. O padrão é colocar _.
separate() faz o contrário. Saca só.
Ela recebe o banco de dados, depois a coluna que você deseja separar, depois um vetor com as colunas nas quais você quer separar, e por fim, uma das possibilidades é você separar pela posição (existem outras), que foi o que fiz adiante, “quebrando” a coluna na segunda posição. Novamente, especifiquei que não queria remover as colunas originais, apenas para finalidade de demonstração.
No caso da PNAD com a qual estamos trabalhando, não é necessário fazer esses ajustes. Mas fica na sua caixinha de ferramentas, caso você precise.
pivot_longer() e pivot_wider()
O objetivo destas funções é reformatar linhas e colunas. Eu acho um pouco complicado explicar o que elas fazem com palavras, acho que uma demonstração visual funciona bem melhor. Vamos ver o que elas fazem com o banco de dados da PNAD.
De maneira sucinta, pivot_wider() “puxa as orelhas” do seu banco de dados, aumentando o seu número de variáveis e diminuindo o número de observações, enquanto pivot_longer() “puxa o pé” dele, diminuindo o número de colunas e aumentando o número de linhas.
Mas porque eu iria querer fazer isso com meu banco? Se você já fez alguma pirâmide etária, sabe que é necessário separar a população masculina da feminina e multiplicar a população masculina por um número negativo. Uma das formas mais eficientes de fazer isso, é separar as observações dos homens e das mulheres em colunas diferentes.
Pra começar, precisamos transformar nosso banco de dados em um conjunto de valores agregados que contém nossa população. Vamos fazer isso com dplyr.
library(dplyr)
(pir_et <- pnad %>%
mutate(idade2 = cut(idade, seq(0, max(idade), 5), right = FALSE)) %>%
group_by(sexo, idade2) %>%
count(wt = peso)
)Note que após essas transformações, ficamos com uma coluna n que tem o número de pessoas nesses grupos de idade e sexo. Para o próximo passo, seria mais fácil se os homens estivessem contados em uma coluna, e as mulheres, em outra.
Moleza! pivot_wider() pegou célula que tinha o valor “Masculino” na variável sexo e colocou numa nova coluna com esse nome, e cada célula que tinha o valor “Feminino” na variável sexo e colocou na coluna “Feminino”. Como em outras funções, começamos especificamos um banco de dados, depois, a coluna de onde saem os “nomes” (Masculino e Feminino) e a coluna de onde saem os valores da célula (n).
Continuando pra nossa pirâmide etária, precisamos que a coluna dos homens esteja negativa e que ambas as colunas estejam em proporção do total. Fazemos isso com mutate(), lembre que é preciso desagrupar o banco!!!
total <- with(pir_et, sum(Masculino, na.rm = TRUE) + sum(Feminino, na.rm = TRUE))
(pir_et <- pir_et %>%
ungroup() %>%
mutate(Masculino2 = (Masculino / total) * -1,
Feminino2 = Feminino / total))Agora é só montar o gráfico com ggplot2.
library(ggplot2)
ggplot(pir_et) +
geom_col(aes(idade2, Masculino2), fill = "blue", na.rm = TRUE) +
geom_col(aes(idade2, Feminino2), fill = "red", na.rm = TRUE) +
coord_flip()## Warning: Removed 2 rows containing missing values (position_stack).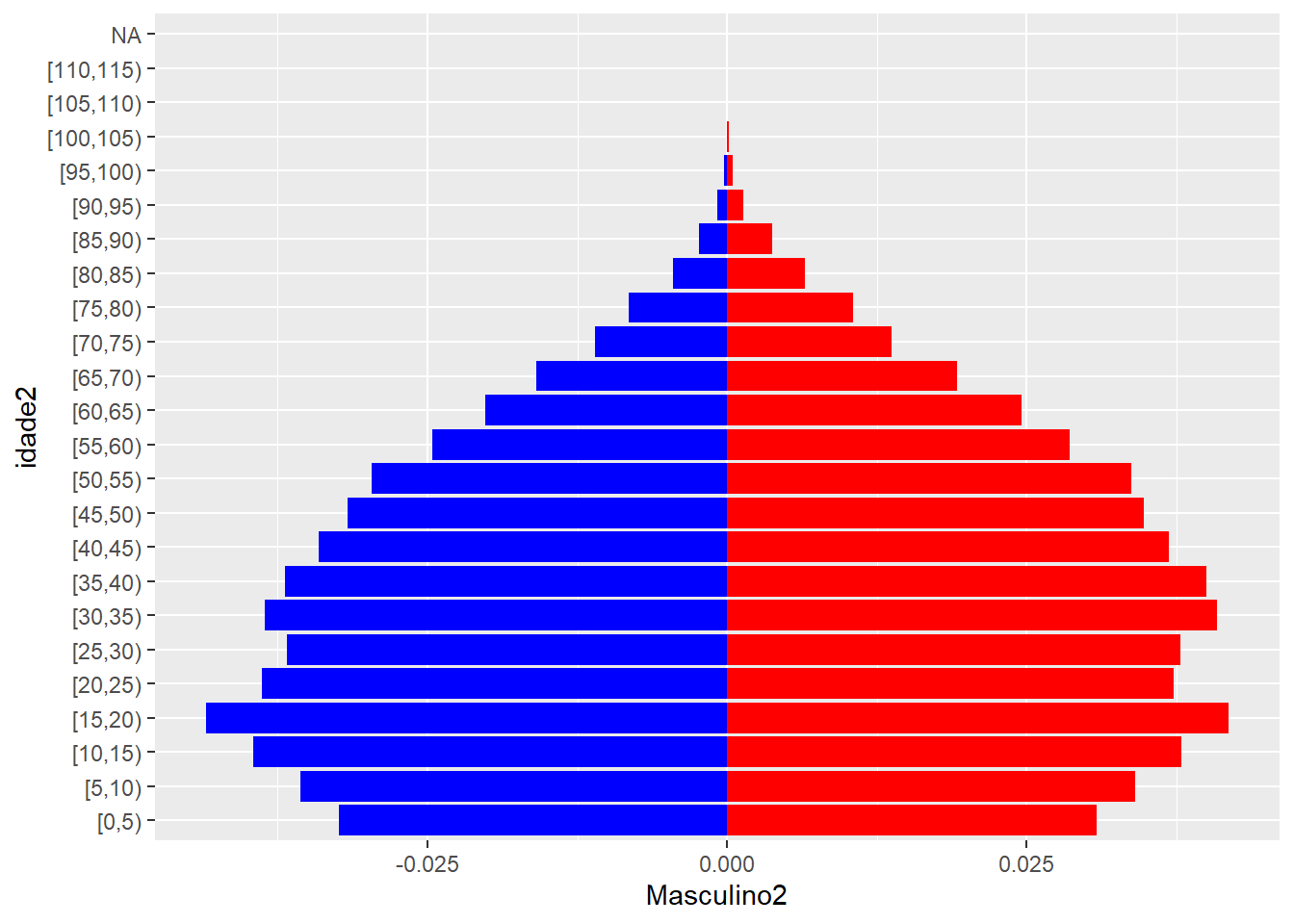
Mas há um jeito um pouco mais elegante de montar esta pirâmide. O resultado final deve ser muito parecido, mas a gente economiza um pouco de código no ggplot. Pra isso, a gente precisa recompor o nosso banco de dados em formato “longo”, com as variáveis Masculino2 e Feminino2 reunidas numa coluna só, que vamos chamar de sexo2. Pra fazer isso, precisaremos aplicar a irmã da pivot_wider().
(pir_et2 <- pivot_longer(
data = pir_et,
cols = c(Masculino2, Feminino2),
names_to = "sexo2",
values_to = "n"
))Agora, nossa chamada pro ggplot2 pode ficar um pouco mais elegante.
## Warning: Removed 2 rows containing missing values (position_stack).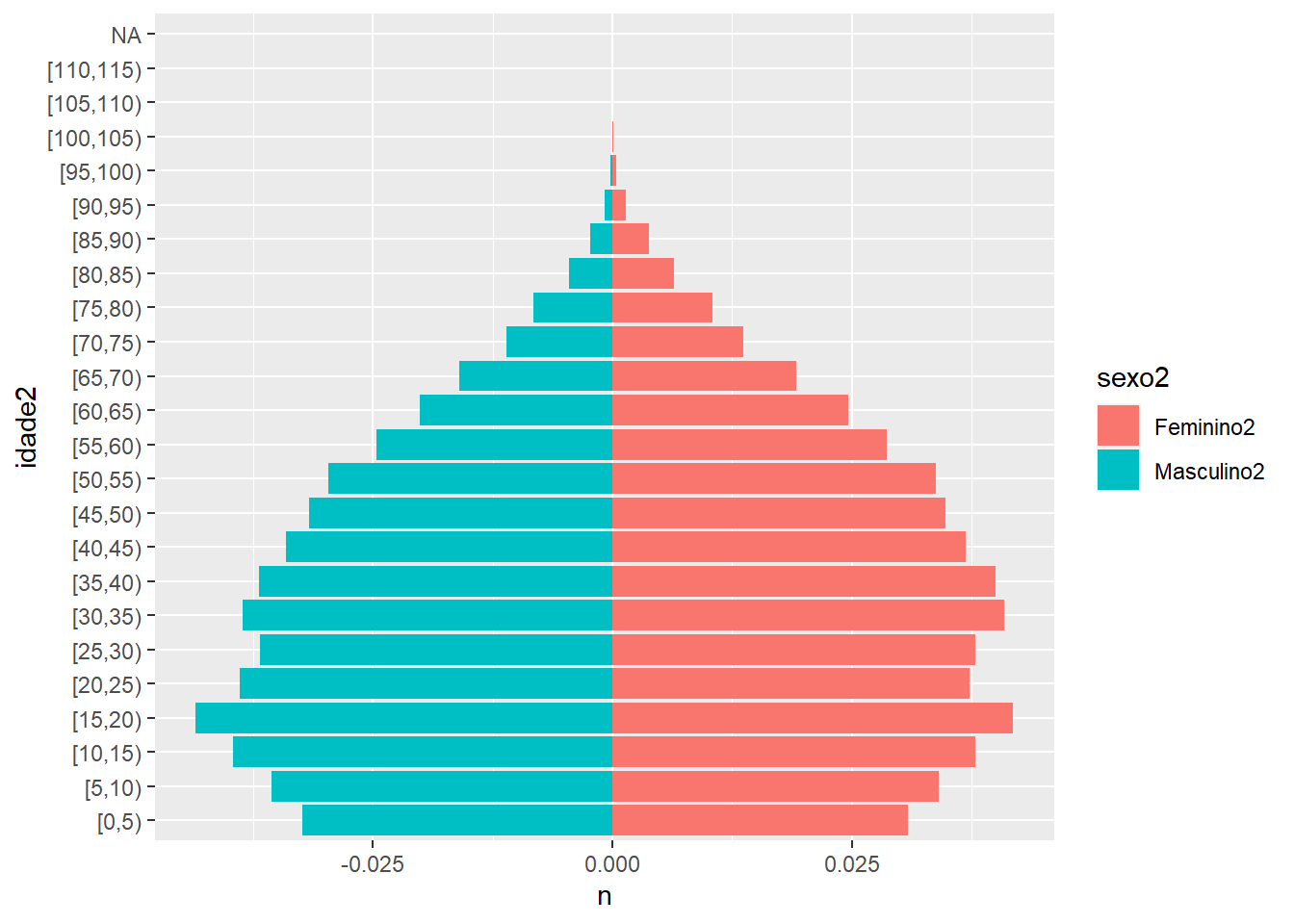
Uma nota sobre valores missing
Quando você reformata um banco de dados, você precisa ter cuidado com os dois tipos de missing:
- Explícito: valores que aparecem no seu banco original como
NA. - Implícitos: valores que seu banco de dados de fato não tem.
Veja o seguinte exemplo:
acoes <- tibble(
ano = c(2015, 2015, 2015, 2015, 2016, 2016, 2016),
trimstr = c( 1, 2, 3, 4, 2, 3, 4),
tx_lcr = c(1.88, 0.59, 0.35, NA, 0.92, 0.17, 2.66)
)Tem DOIS valores missing nesse banco:
- O lucro do 4 trimestre de 2015 é um missing explícito, porque ele aparece no dataset como NA.
- O lucro do primeiro trimestre de 2016 é um missing implícito, porque ele nem aparece no banco.
É preciso ficar atento a esta questão quando se usa pivot_longer() e pivot_wider(), e no R for Data Science, Wickham & Grolemund entram em mais detalhes, mas, pra não complicar desnecessariamente a questão, resolvi não incluí-la por aqui.
Exercícios
Descreva brevemente o que seria um banco de dados “tidy”.
Descreva brevemente como as 4 funções do tidyr transformam o dado para produzir seus resultados.
Porque
pivot_longer()epivot_wider()não são perfeitamente simétricas? Considere o exemplo a seguir:
stocks <- tibble(
year = c(2015, 2015, 2016, 2016),
half = c( 1, 2, 1, 2),
return = c(1.88, 0.59, 0.92, 0.17)
)
stocks %>%
pivot_wider(names_from = year, values_from = return) %>%
pivot_longer(`2015`:`2016`, names_to = "year", values_to = "return")Dica: Preste atenção nos valores de “return” por ano e no “nome” que você daria pra cada coluna.
- O que aconteceria se você “alargasse” essa tabela? Como você poderia adicionar uma nova coluna para identificar cada valor de maneira única?
pessoas <- tribble(
~nome, ~nomes, ~valores,
#------------------|--------|--------
"Felipe Madeira", "idade", 45,
"Felipe Madeira", "altura", 186,
"Felipe Madeira", "idade", 50,
"Jéssica Cordeiro", "idade", 37,
"Jéssica Cordeiro", "altura", 156
)- Transforme a seguinte tabela em “tidy data”. O que você precisa fazer? Alargar ou alongar?
- O que fazem os argumentos
extraefillemseparate()? Experimente com as várias opções usando os dados de exemplo abaixo:
## Warning: Expected 3 pieces. Additional pieces discarded in 1 rows [2].## Warning: Expected 3 pieces. Missing pieces filled with `NA` in 1 rows
## [2].Faça pirâmides etárias para 3 ufs diferentes e compare-as.
Decore o gráfico da pirâmide com títulos, fonte, legendas, etc.
Copyright © 2020 Vinícius Maia. Nenhum Direito a menos.