Falando a língua do R
08/04/2020
Introdução
Uma das grandes dificuldades de aprender uma nova língua é o estranhamento. Mesmo quando você entende o significado de algumas palavras, é difícil entender a síntaxe das frases, mesmo quando entende a síntaxe de algumas frases básicas, é difícil compreender as formas como as pessoas se referem aos objetos da língua. Com linguagens de programação, não é diferente, na verdade, se você não vem de uma base sólida em matemática e lógica, pode parecer uma tarefa impossível. Mas não é!
O objetivo desta atividade é te dar um primeiro ponto de contato com a linguagem R, para suavizar esse estranhamento com todos os novos conceitos que são rapidamente introduzidos em tutoriais que estão mais focados nas ferramentas utilizadas no trabalho diário com dados. Espero que você pegue o gosto e estimule sua curiosidade e criatividade!
Instalação
O R Base é nada mais que um console onde você pode digitar comandos e obter respostas do software, para facilitar não só o aprendizado, mas o trabalho diário, eu recomendo fortemente você utilizar um Ambiente de Desenvolvimento Integrado. Nele, você vai poder utilizar não só o console do R base, como vai obter vários painéis que te ajudam a acompanhar o que está ocorrendo no seu programa. Eu recomendo o RStudio.
- Instale o R Base
Selecione o seu sistema operacional (o meu é Windows)
Clique em “base”
Clique para fazer o download da versão mais recente
Rode o instalador e siga as instruções.
- Instale o RStudio
Abra o site do Rstudio e clique em Download
Role para baixo até chegar na parte indicada abaixo
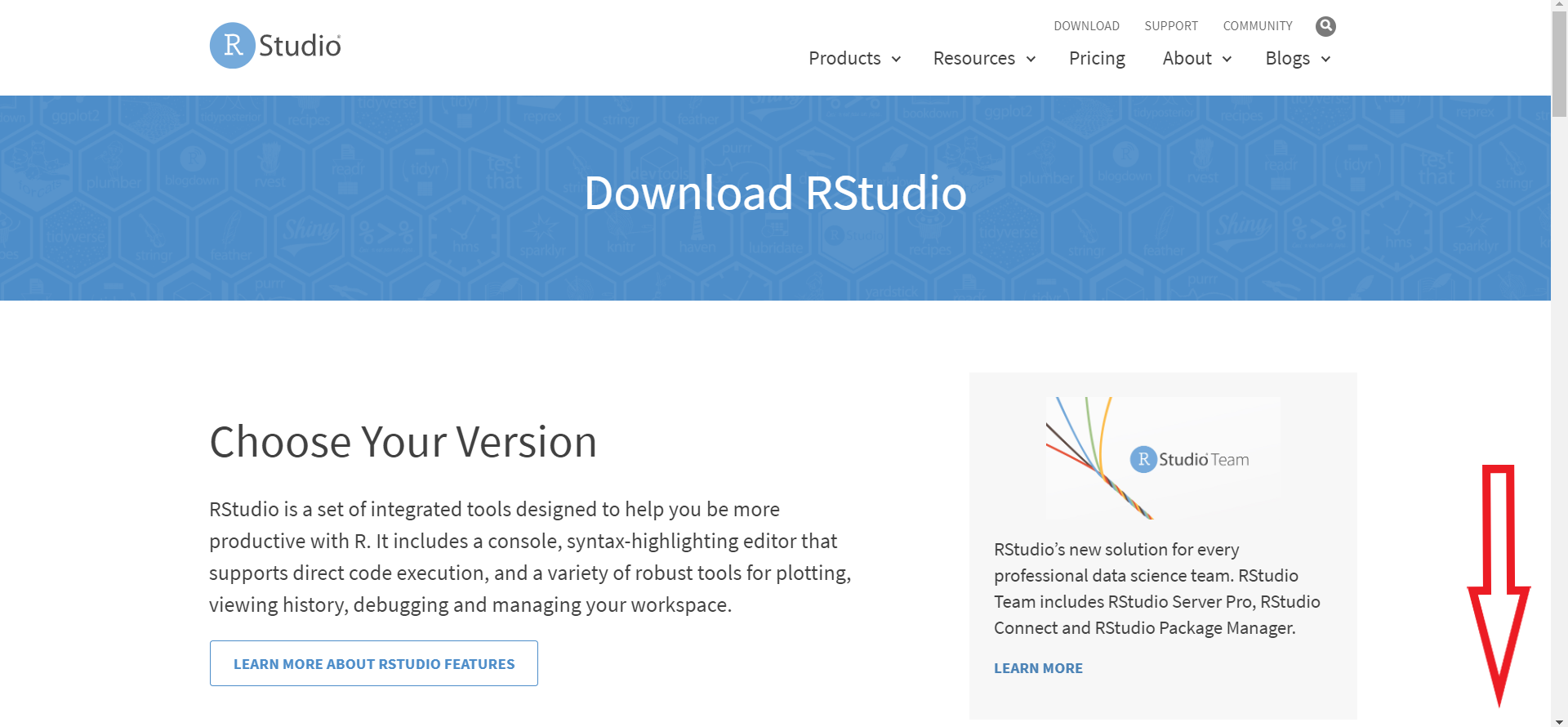
Selecione o Rstudio para usuários (gratuito)
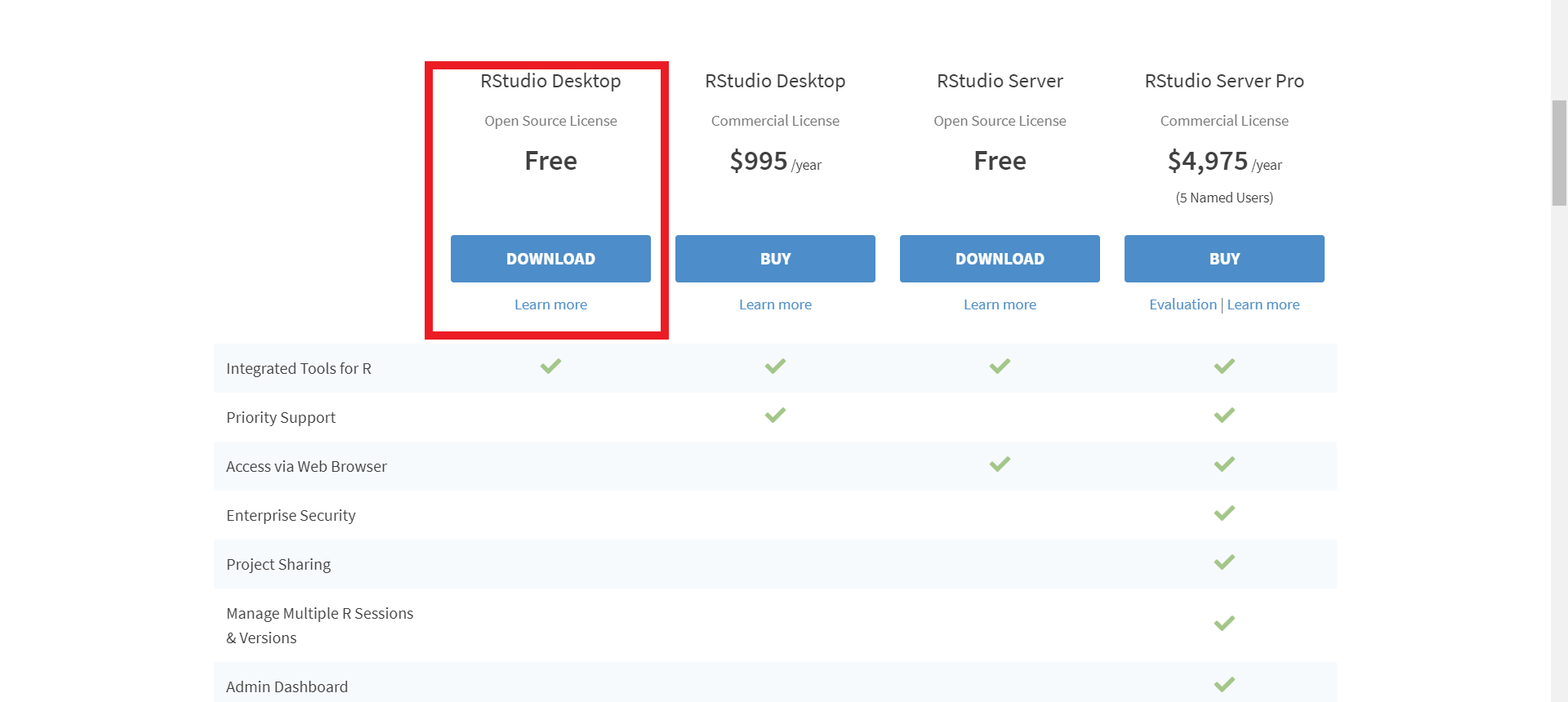
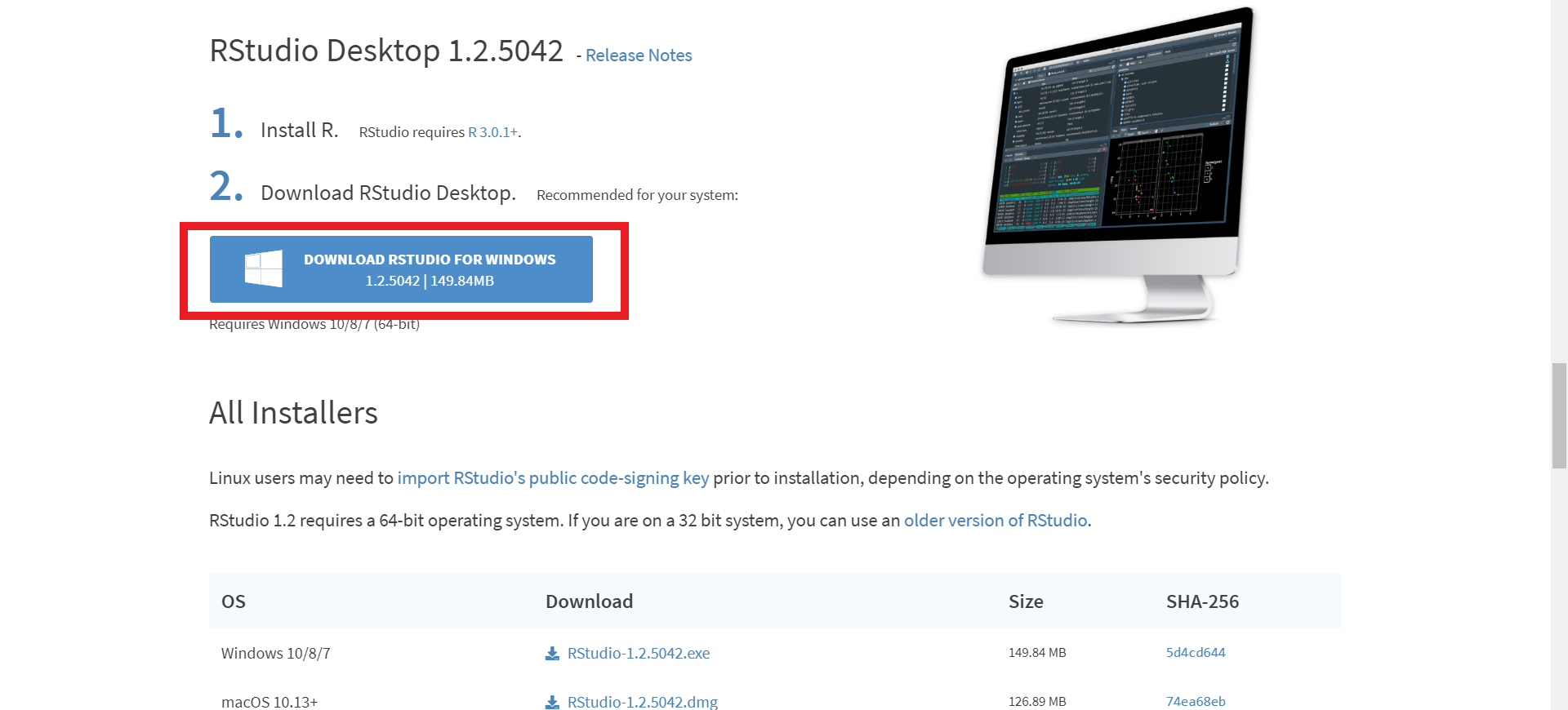
Clique no botão de download indicado
O que é o R?
No contexto do uso do R na demografia, creio que é interessante a gente olhar para ele a partir de duas perspectivas:
É uma linguagem de programação interpretada, com ênfase na estatística, na ciência de dados. É muito utilizada por biológos, estatísticos e alguns cientistas sociais quantitativos, como economistas, cientistas políticos, etc.
É uma caixinha de ferramentas, onde muitas das operações que iremos realizar já foram programadas por outros cientistas que vieram antes de nós, o que reduz a necessidade de programar tudo manualmente.
Pra que estudar R?
Em último caso, essa resposta é pessoal e subjetiva, afinal, como cientistas sociais ou demógrafos, existem outras opções por aí para trabalhar seus bancos de dados, mas deixo aqui algumas razões que me ajudaram a decidir.
- R é gratuito para usuários, sem precisar comprar nem registrar nada.
- É desenvolvido de maneira colaborativa, por cientistas, acadêmicos e programadores que doam seu trabalho para a comunidade.
- É um dos softwares mais atualizados, recebendo novas funcionalidades o tempo todo.
- Permite interface com todos os outros softwares estatísticos, lendo e escrevendo bancos de dados SPSS, SAS, EXCEL, STATA.
- Um dos mais completos, com pacotes e funções para praticamente tudo que você imaginar, inclusive com alguns para a demografia.
O Console do R
Se vocês trabalharem no console do R, ele funciona como uma espécie de calculadora científica. Para finalidades de demonstração, vou utilizar a aba “Console” do RStudio. Não é necessário abrir o software R, pois o RStudio deve conectar-se automaticamente a versão mais recente do R.
Experimente rodar (digitar e apertar ENTER) os comandos a seguir diretamente no console:
## [1] 4## [1] 4## [1] 4## [1] 4## [1] 0.6931472## [1] 0.30103## [1] FALSE## [1] FALSE## [1] TRUE## [1] "banana"Veja que alguns comandos funcionam corretamente, enquanto outros dão erros. É sempre uma boa ideia inspecionar os erros para descobrir o que está acontecendo. No caso de 2 + 2w, o R não reconhece o w como algo que pode fazer parte de uma operação de soma. As " ao redor de banana indicam que se tratam de caracteres, o que frequentemente é chamado de string.
Códigos precisam ser organizados visualmente. Para o computador, tanto faz, se o código estiver correto, ele será executido sem erros, mas para o ser humano que programa, a organização do texto é fundamental. Considere o código a seguir (não o rode):
setwd("C:/RBook/")
ISIT<-read.table("ISIT.txt",header=TRUE)
library(lattice)
xyplot(SourcesSampleDepth|factor(Station),data=ISIT,
xlab="Sample Depth",ylab="Sources",
strip=function(bg=’white’, ...)
strip.default(bg=’white’, ...),
panel = function(x, y) {
panel.grid(h=-1, v= 2)
I1<-order(x)
llines(x[I1], y[I1],col=1)})Dentro de um determinado contexto, esse código funciona perfeitamente, mas para o leitor, esse código é difícil de interpretar. Mesmo sem saber do que se trata, considere as seguintes alterações:
setwd("C:/RBook/")
ISIT<-read.table("ISIT.txt",header=TRUE)
#Comece a plotagem
#Plote Sources como função de SampleDeth, e use uma
#caixa para cada estação.
#Use a cor preta (col=1), e específique os nomes (labels)
#dos eixos x e y (xlab and ylab). Use o fundo branco nas
#caixas que contém os nomes das estações
xyplot(SourcesSampleDepth|factor(Station),
data = ISIT,xlab="Sample Depth",ylab="Sources",
strip=function(bg=’white’, ...)
strip.default(bg=’white’, ...),
panel = function(x,y) {
#Adicione linhas de grade
#Evite gráficos “espaguete”
#Plote os dados como linhas (de cor preta)
panel.grid(h=-1,v= 2)
I1<-order(x)
llines(x[I1],y[I1],col=1)})A inserção de algumas linhas de comentário (iniciadas com #) nos ajuda a compreender qual o objetivo daquele código, o que facilita a leitura.
#Read data
setwd("C:/RBook/")
ISIT <- read.table("ISIT.txt", header = TRUE)
#Load the lattice package
library(lattice)
#Start the actual plotting
#Plot Sources as a function of SampleDepth, and use a
#panel for each station.
#Use the colour black (col=1), and specify x and y
#labels (xlab and ylab). Use white background in the
#boxes that contain the labels for station
xyplot(Sources SampleDepth | factor(Station),
data = ISIT,
xlab = "Sample Depth", ylab = "Sources",
strip = function(bg = ’white’, ...)
strip.default(bg = ’white’, ...),
panel = function(x, y) {
#Add grid lines
#Avoid spaghetti plots
#plot the data as lines (in the colour black)
panel.grid(h = -1, v = 2)
I1 <- order(x)
llines(x[I1], y[I1], col = 1)})A inserção de espaços a esquerda do código (identação) nos ajuda a entender relações de subordinação. O que esta identado a direita está subordinado a parte não identada acima. Junto com os comentários, já se torna possível depreender um pouco mais o sentido do código. Neste caso, trata-se da leitura de um banco de dados e da construção de um gráfico (xyplot), bem como da especificação de algumas características desse gráfico.
Porque não trabalhar diretamente no console
Quando programamos diretamente no console, estamos nos submetendo a nossa memória. Será que já executamos aquela operação? Será que já fizemos aquele passo intermediário para chegar ao resultado final? À medida que nossas tarefas se tornam mais complexas, lembrar-se de cada etapa se torna impossível. Ainda mais considerando que você deve querer salvar seus programas para reutilizá-los no futuro. Para isto, utilizaremos programas (chamados de scripts) que ficam abertos no painel “Source” do Rstudio. Abra seu primeiro script clicando em File >> New File >> R Script, ou pelo atalho, Ctrl + Shift + N.
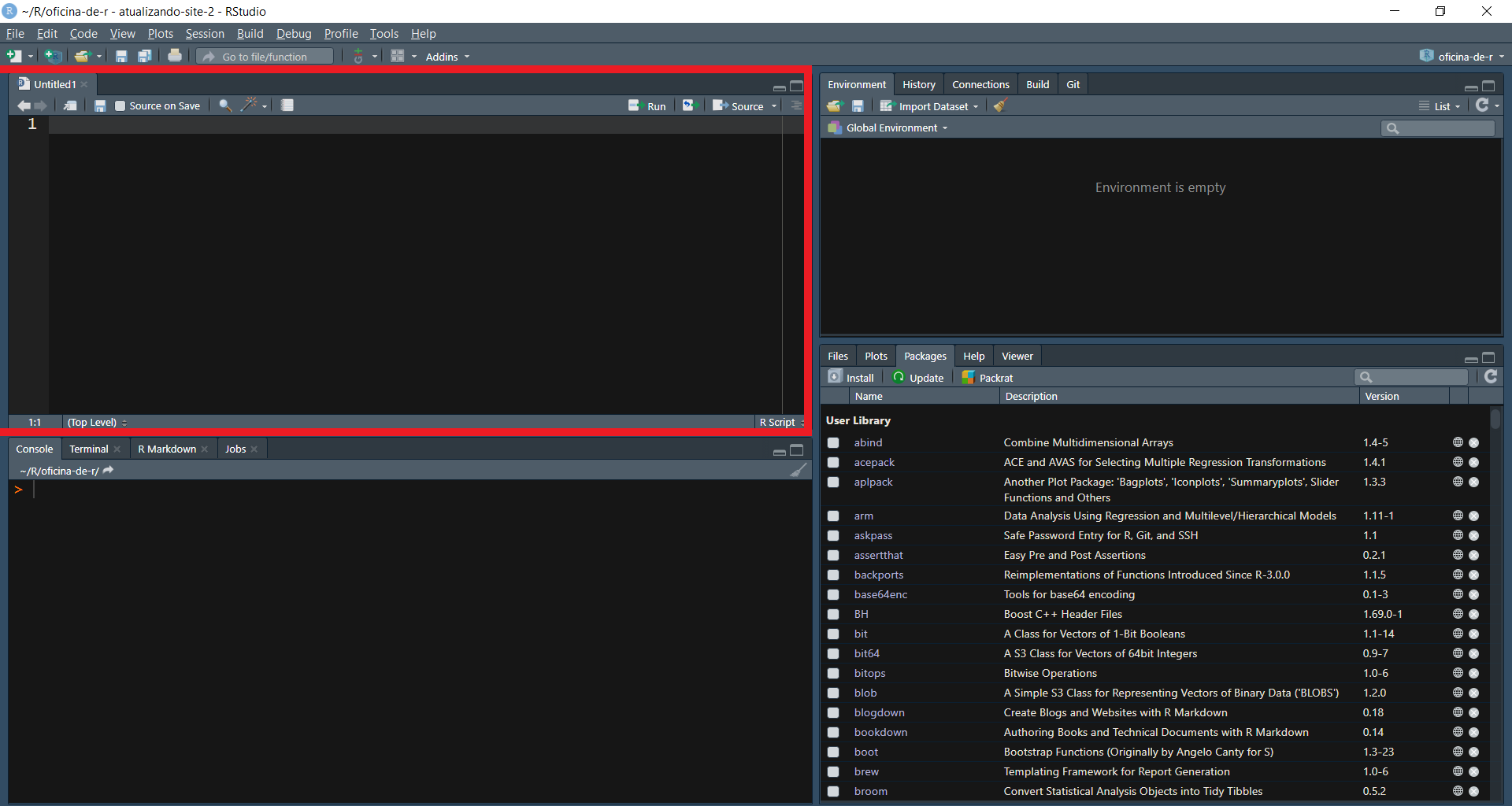
A ideia aqui é escrever um código que fica salvo em um arquivo (script) e que pode ser rodado no console usando o atalho Ctrl + Enter.
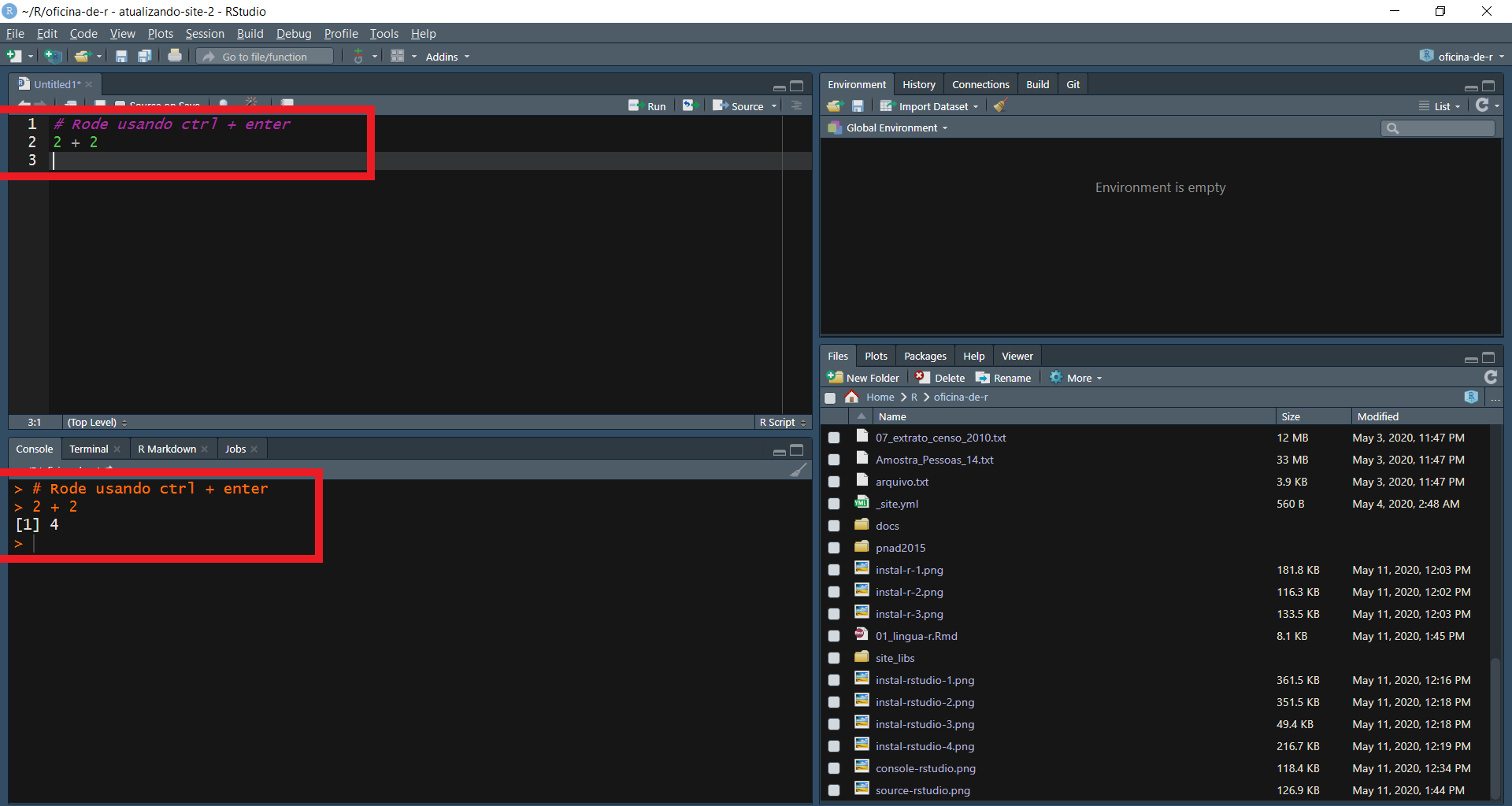
Assim, o que você estiver escrito naquela linha/bloco de código vai ser rodada e você pode ver o resultado no console embaixo.
Ajuda do R
Uma das coisas que muda se você veio de uma Interface Gráfica de Usuário como no SPSS ou Excel, é que você precisa consultar a documentação do programa frequentemente, afinal, ninguém é um computador pra lembrar do nome de todos os comandos de cabeça. Vamos ver algumas opções no R.
Primeiro, vamos pedir ajuda sobre a função '+'.
As duas opções chamam a ajuda do R, que aparece na aba Help.
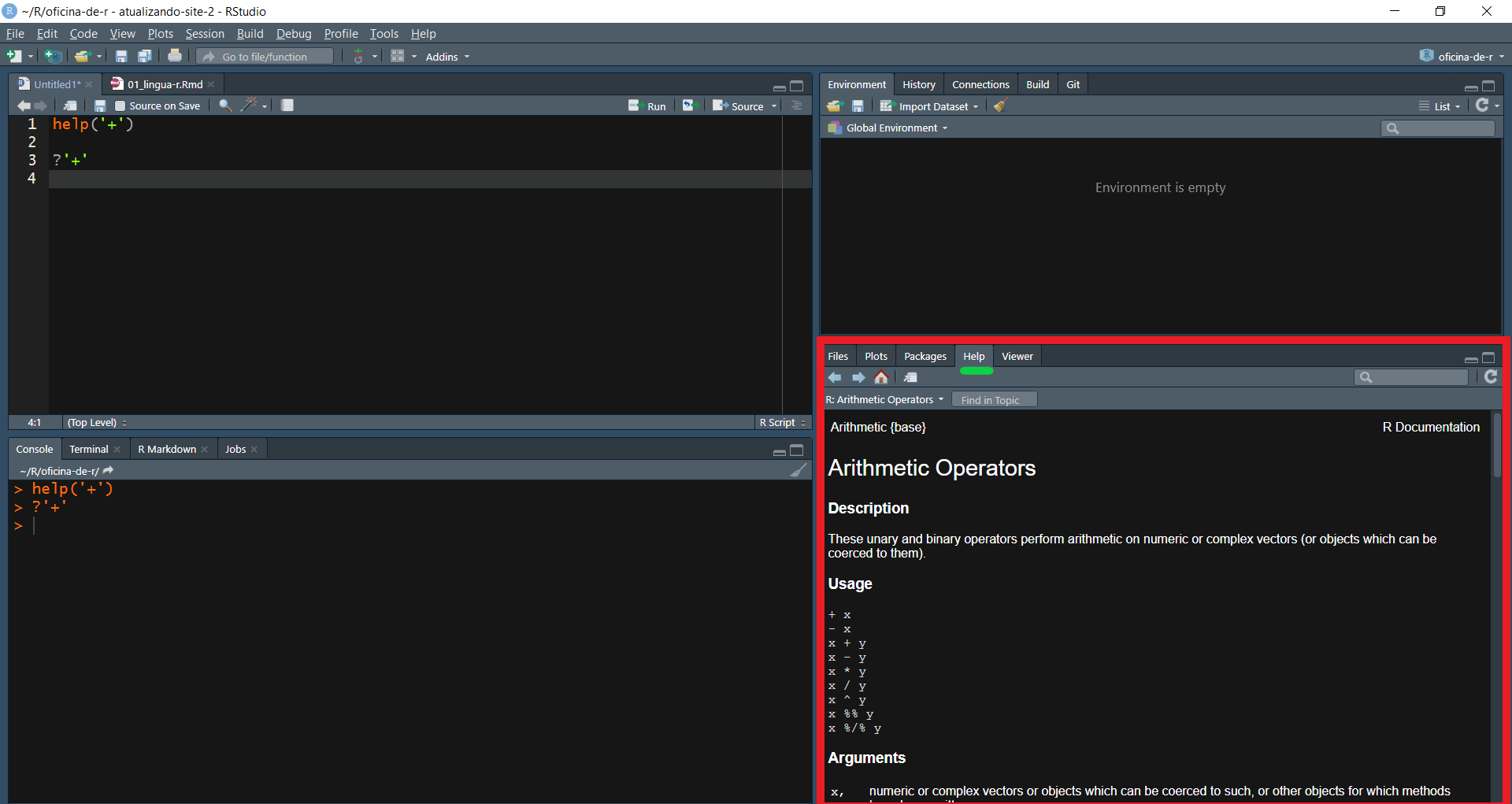
Outras opções são procurar no Site do R, no Google, no Stack Overflow ou na Lista R-Br.
Muitos pacotes no R vem com tutoriais feitos por seus criadores. Para ver uma lista de tutoriais disponíveis, use:
Que deve abrir uma lista no seu navegador. Se você já sabe qual vignette quer ler, pode abrí-la diretamente no Rstudio com:
Falando a língua do R
À medida que você começa a utilizar o R, vários termos começar a se repetir na documentação e nos fóruns, e é difícil conseguir se orientar sem saber pelo menos um pouco do seu significado e de como eles se relacionam entre si. São conceitos básicos de programação e alguns específicos da língua, então trate isso como uma aula introdutória de alemão. É difícil, mas por trás disso há uma lógica e uma comunicação eficaz (pelo menos para os alemães!).
Síntaxe
Aqui utilizo o termo sintaxe como aquela parte da gramática que se refere a função de cada termo de uma frase e a posição adequada para este. Se eu coloco a frase: “Pizza comer adoro eu” desta forma, a maioria de vocês apontaria que seus termos estão na ordem errada. Isto ocorre porque vocês tem uma noção de como deve ser a síntaxe de uma frase em português, quem vem primeiro e quem vem depois.
Da mesma forma, no R a síntaxe é importante.
## [1] 1 2 3 4 5 6 7 8 9 10## [1] 55## [1] 0.01818182 0.03636364 0.05454545 0.07272727 0.09090909 0.10909091
## [7] 0.12727273 0.14545455 0.16363636 0.18181818A linguagem espera que as operações ocorram em uma determinada ordem, dada pelas regras estabelecidas pelos seus programadores, retiradas de convenções geralmente aceitas e também da lógica matemática. Se você receber um erro ou uma dica para “melhorar” ou “corrigir” sua sintaxe, é geralmente a isso que se refere.
Funções e métodos
Tudo em R é feito através de funções e métodos. A melhor maneira de entender uma função é pensar em uma máquina. Vou dar o exemplo dos eletrodomésticos que temos na cozinha. O liquidificador é responsável por transformar sólidos em líquidos. Assim, ele recebe algo sólido e produz algo líquido ao final de sua operação. O fogão é responsável por cozinhar alimentos, então ele recebe alimentos crus e produz alimentos cozidos ao final da sua operação.
Assim são as funções, elas recebem entradas, nas quais executam operações específicas e emitem resultados de acordo com a função.
## [1] 55## [1] 5.5Existem diferentes tipos de liquidificadores e fogões, que são aplicados para propósitos específicos. Por exemplo, se você quer fazer um creme usando cenouras, provavelmente o seu liquidificador caseiro precisará que você coloque a cenoura já cortada em pedaços menores, pois ele não tem a potência necessária para triturar a cenoura inteira adequadamente. Por outro lado, um liquidificador industrial pode detonar uma caixa de cenouras inteira sem problema.
Essa analogia nos leva para a questão dos métodos e também das entradas das funções.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.00 3.25 5.50 5.50 7.75 10.00# Emite as medidas resumo de uma tabela (data.frame)
y <- letters[1:10]
df <- data.frame(x, y)
summary(df)## x y
## Min. : 1.00 Length:10
## 1st Qu.: 3.25 Class :character
## Median : 5.50 Mode :character
## Mean : 5.50
## 3rd Qu.: 7.75
## Max. :10.00Determinadas funções só vão aceitar determinadas entradas, enquanto outras funções vão ser “genéricas”, despachando o método mais adequado para o tipo de dado que você submeter.
Argumento
Argumentos são as características que você passa pra sua função. No nosso exemplo do liquidificador, eu poderia passar 3 argumentos:
- Os ingredientes a serem liquidificados
- A velocidade do aparelho (1, 2 ou 3)
- O tempo de operação em minutos
No caso da função soma, há um argumento opcional sobre como devem ser tratados os valores desconhecidos.
## [1] 1 2 3 4 5 6 7 8 9 NA## [1] NA## [1] 45(Quase) todas as funções recebem argumentos, e eles podem alterar o funcionamento “padrão” de uma função de acordo com as suas necessidades.
Objetos
Na nossa empreitada culinária, precisaremos utilizar potes, panelas e depósitos para armanezar nossos ingredientes e também nossos pratos prontos. Os objetos em R são contêineres de diversos tipos e formatos nos quais podemos armazenar informações.
Vejamos um objeto que criamos agora há pouco, usando a função <-.
## [1] 1 2 3 4 5 6 7 8 9 10Esse tipo de objeto se chama “vetor”, e ele é geralmente uma coluna de informações de mesmo tipo, guardada em um objeto de mesmo nome. No caso, é um vetor de números inteiros que vai de 1 a 10. Há muitos tipos de objetos em R, e podemos até filosofar que tudo é um objeto, afinal, as funções são também objetos guardados numa função com seu nome. Mas isso é menos importante.
Objetos são os nossos potes e panelas, onde armazenamos informações relevantes em formatos específicos. Os dois objetos que mais utilizaremos daqui em diante são os vetores e os data.frames.
## [1] 1 2 3 4## [1] "a" "b" "c" "d"## [1] TRUE FALSE TRUE TRUE# Data.frames são criado com data.frame()
data.frame(a = c(1, 2, 3, 4),
b = c("a", "b", "c", "d"),
c = c(TRUE, FALSE, TRUE, TRUE))Tipos de dado
Voltando para nossa metáfora culinária, podemos encontrar diversos tipos de ingredientes. Alguns deles servem para formar a base de uma refeição, como o nosso feijão-com-arroz, enquanto outros oferecem mais sabor, como o sal e a pimenta. Outros estão entre uma coisa e outra, como o refogado de cebola, alho e cenoura.
No R, nossos objetos tem tipos distintos, alguns são números, outros são letras e palavras, outros são valores lógicos e outros são objetos complexos, compostos de vários objetos menores de vários tipos. Podemos descobrir o tipo dos objetos assim:
## [1] "integer"## [1] "character"## [1] "data.frame"Também podemos converter entre os tipos usando a família de funções as.___
## [1] 1.1 2.2 3.3 4.4## [1] 1 2 3 4## [1] "1.1" "2.2" "3.3" "4.4"## [1] 1 0 1 0## [1] "TRUE" "FALSE" "TRUE" "FALSE"## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j"## Warning: NAs introduced by coercion## [1] NA NA NA NA NA NA NA NA NA NAAlgumas funções básicas muito úteis.
## [1] 3## [1] 4 4 4## [1] 2## [1] 4## [1] 6## [1] 0## [1] 2## 0% 25% 50% 75% 100%
## 1.0 1.5 2.0 2.5 3.0## [1] 1## [1] 1## [1] 1 3## [1] 1## [1] 3# Colagem de caracteres (strings)
# Strings individuais
a1 <- "Eu"
a2 <- "Amo"
a3 <- "Pizza."
paste(a1, a2, a3, sep = " ")## [1] "Eu Amo Pizza."## [1] "Eu Amo Pizza."Errando
Invariavelmente, ao desenvolver seus programas, você cometerá ou encontrará erros. Não entre em pânico! Procure se informar sobre o seu erro. Localize o ponto ele ocorreu e tente ler as mensagens de erro, procure mais informações até que você consiga solucionar seu problema. Vale postar dúvidas em fóruns e ligar pro seu coleguinha que já tem mais experiência, só não vale desistir!
## [1] "Palavra"## [1] 6No começo, pode ser difícil interpretar as mensagens de erro, mas elas geralmente oferecem pelo menos uma ideia de onde procurar o problema. Eu mesmo já resolvi vários problemas copiando e colando a mensagem no google e lendo as respostas das pessoas. Algumas são bem óbvias e tranquilas, outras são mais técnicas e complexas, mas você sempre aprende algo pelo caminho.
Gráficos
Uma das melhores funcionalidades do R é a sua suite de visualizações. Aqui, não vamos nos deter numa explicação detalhada do funcionamento de cada parâmetro gráfico das funções, apenas demonstrar algumas funcionalidades e exemplos interessantes. Voltaremos a esse assunto no futuro. Os exemplos são adaptados do excelente R Data Visualization Cookbook. Os dados utilizados foram retirados do World Bank Data.
Para que os scripts a seguir funcionem, vocês vão precisar que os arquivos de dados estejam localizados em sua pasta de trabalho, que vocês podem alterar como quiserem, basta especificar o caminho desejado de pasta.
setwd("C:/Users/vinic/Documents/R") # Substitua pela sua pasta desejada
# OU
setwd("C:\\Users\\vinic\\Documents\\R")Atenção às contrabarras se você copiar o caminho do arquivo direto do Windows!
Um scatterplot
if ((!"grDevices" %in% installed.packages())) {
install.packages("ISLR")
}
library(ISLR)
attach(Carseats)
head(Carseats)plot(Income, Sales,
col = c(Urban),
pch = 20,
main = "Vendas de Cadeirinhas Infantis para automóveis",
xlab = "Renda (milhares de Dólares)",
ylab = "Unidades vendidas (milhares)"
)
legend("topright",
cex = 0.6,
fill = c("red", "black"),
legend = c("Urbana", "Não-urbana"))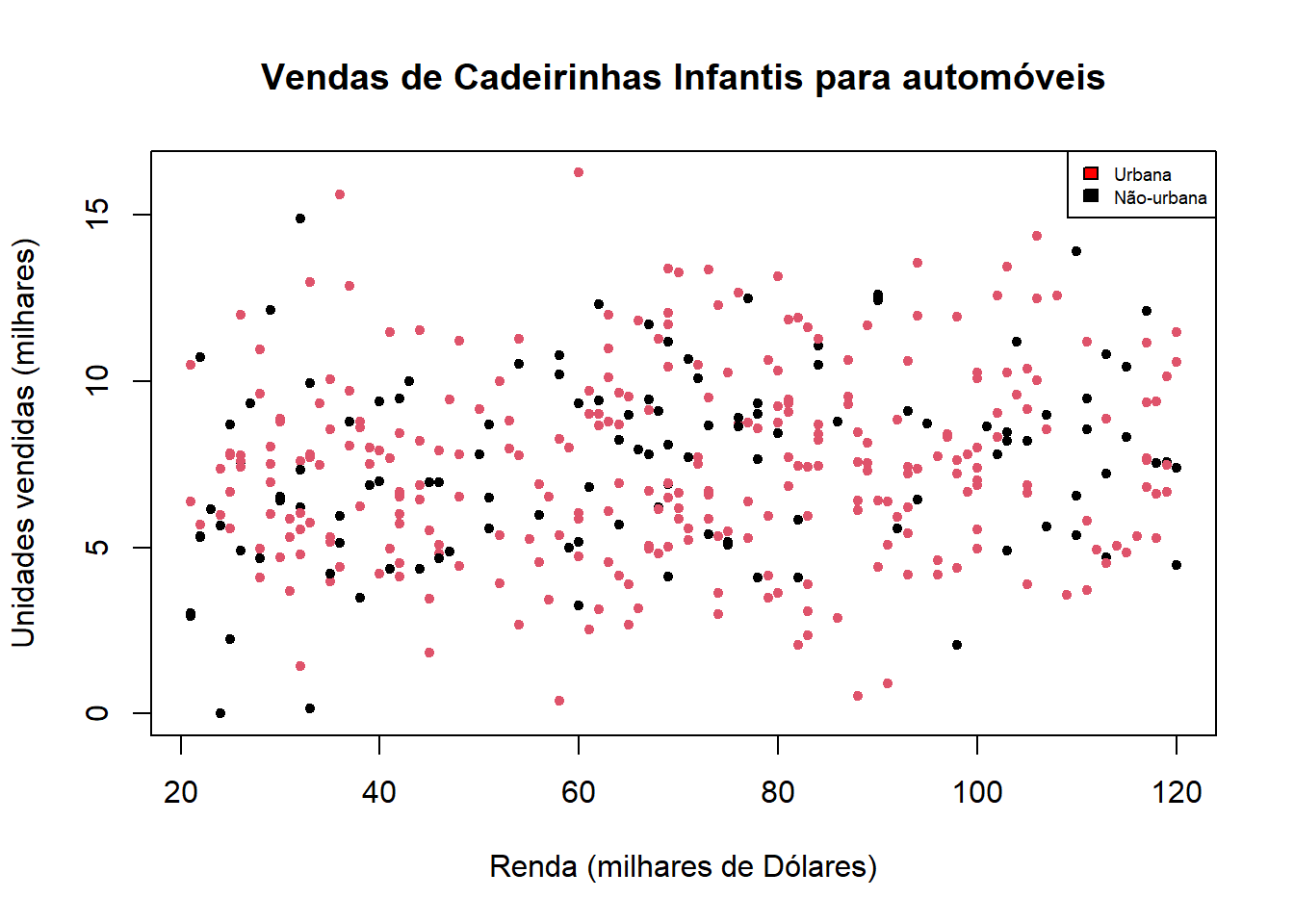
Um scatterplot com alguns detalhes a mais
## Country.Name chmort gdp
## Length:195 Min. : 1.400 Min. : 42587780
## Class :character 1st Qu.: 6.025 1st Qu.: 7353896000
## Mode :character Median :14.300 Median : 34409230000
## Mean :21.339 Mean : 431342787495
## 3rd Qu.:32.850 3rd Qu.: 220038400000
## Max. :84.500 Max. :20544340000000
## NA's :9
## gdp_bil
## Min. : 0.043
## 1st Qu.: 7.354
## Median : 34.409
## Mean : 431.343
## 3rd Qu.: 220.038
## Max. :20544.340
## # Esqueleto
plot(child$gdp_bil, child$chmort,
pch = 20,
col = "#756bb1",
xlim = c(0, max(child$gdp_bil, na.rm = TRUE)),
ylim = c(0, 90),
xlab = "PIB em Bilhões de dólares atuais",
ylab = "Taxa de mortalidade infantil",
main = "Taxa de mortalidade infantil em alguns países em 2018")
# Detalhes
abline(h = mean(child$chmort, na.rm = T), lwd = 1, col = "red")
text(19600,9,labels = c("Estados Unidos"), cex = 0.75)
text(2000, 88, labels = c("República Centroafricana"), col = "red", cex = 0.75)
text(10000, 25,labels = c("Mortalidade infantil média"), col = "red", cex = 0.75)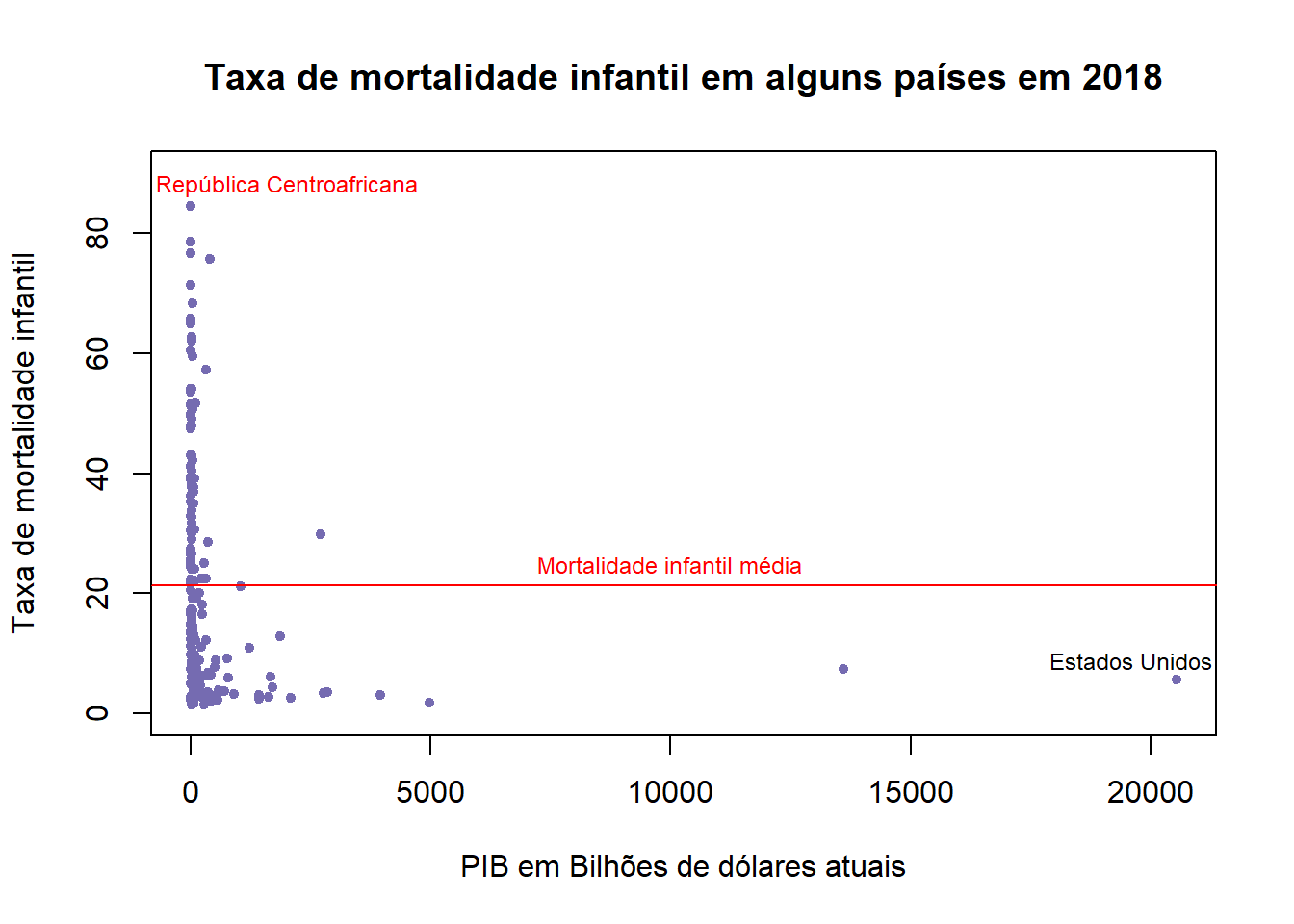
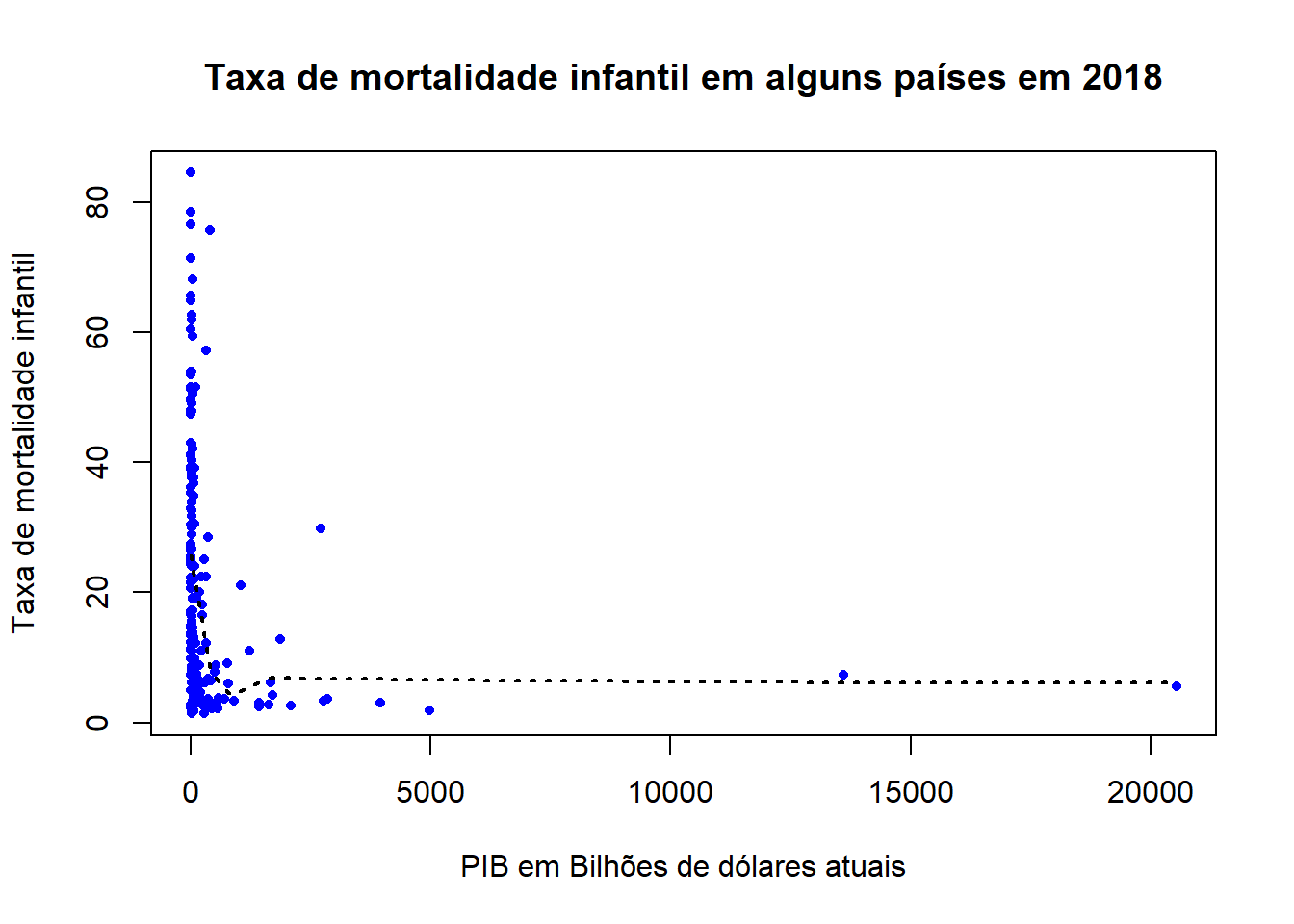
Outra versão do mesmo gráfico, com linha de tendência:
# Linha de tendência
scatter.smooth(
child$gdp_bil,
child$chmort,
span = 1/2,
pch = 20,
lwd = 0.75,
col = "Blue",
lpars = list(lty = 3, col = "black", lwd = 2),
xlab = "PIB em Bilhões de dólares atuais",
ylab = "Taxa de mortalidade infantil",
main = "Taxa de mortalidade infantil em alguns países em 2018"
)
Evolução temporal da desigualdade - gráfico de linha
income <- read.csv2("banco_mundial_desigualdade.csv")
income$Year <- factor(income$Year, ordered = TRUE)
head(income)plot(
income$GDP_bil,
income$gini_coef,
pch = 20,
col = factor(income$President),
type = "o",
xlab = "PIB dos EUA (em bilhões de USD)",
ylab = "Coeficiente de Gini",
main = "Desigualdade nos EUA",
xaxp = c(0, 18000, 8)
)
legend(
"bottomright",
fill = c(6, 1, 4, 2, 7, 3, 13),
legend = c("Obama", "Bush Jr.", "Clinton", "Bush Sr.", "Reagan",
"Carter", "Ford"),
bty = "n",
cex = 0.7
)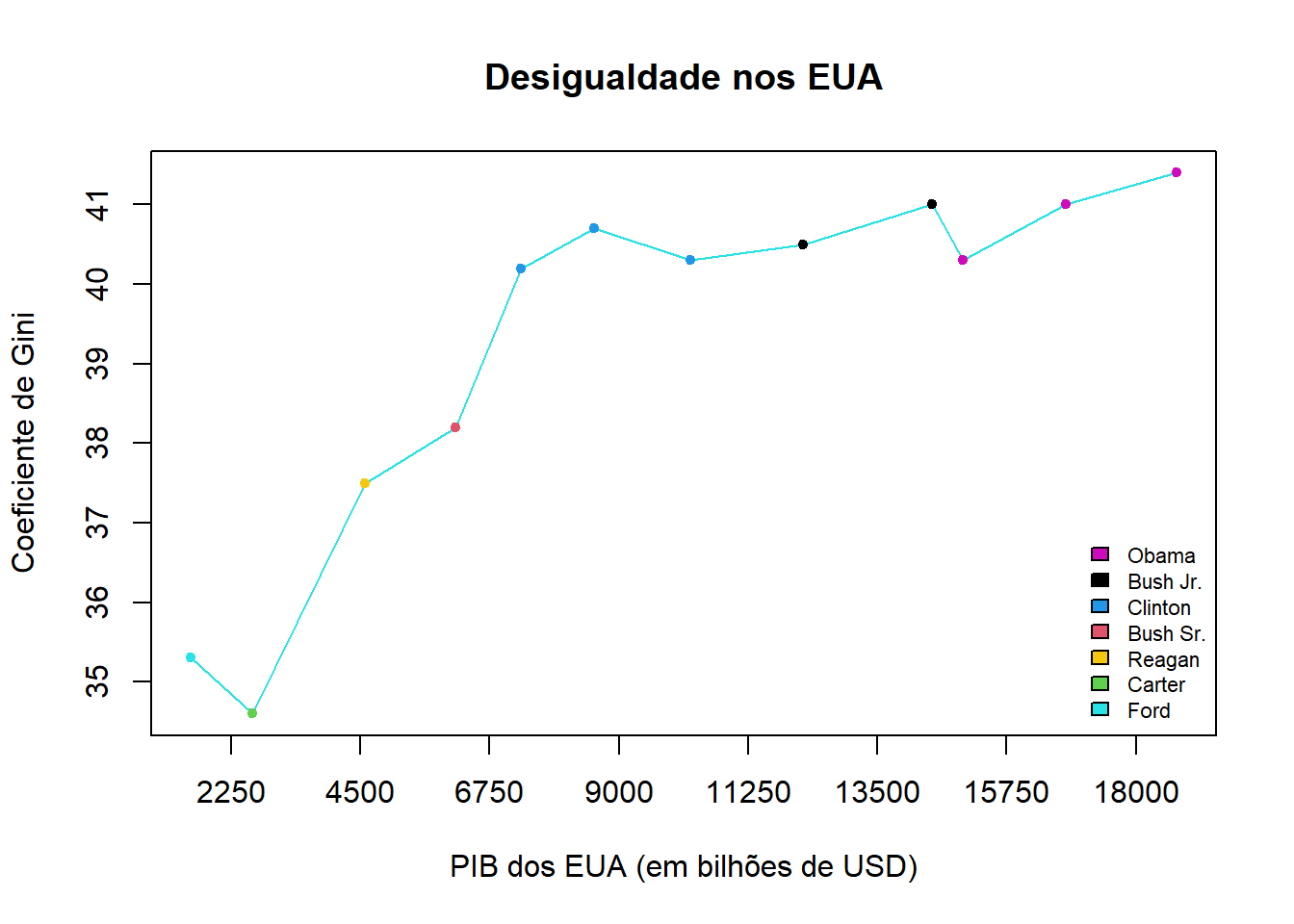
Gráfico de barras comparando valores de variáveis categóricas
par(mar = c(8,4,5,2))
barplot(
imr$IMR,
las = 2,
names.arg = imr$Country,
border = NA,
ylim = c(0, 70),
col = "#e34a33",
main = "Taxas de mortalidade infantil na Ásia Meridional, 2011"
)
abline(h = mean(imr$IMR),
lwd = 2,
col = "white",
lty = 2)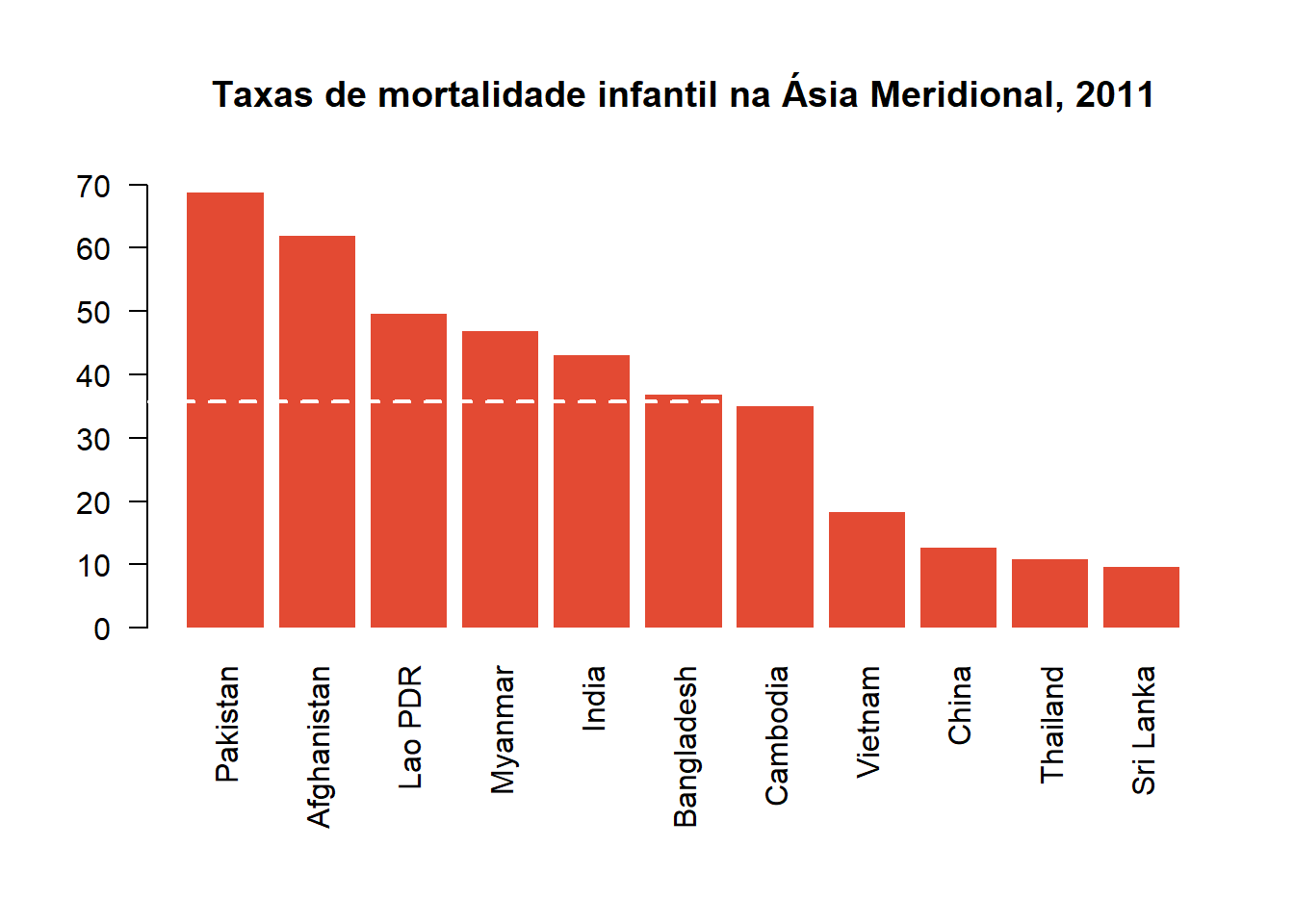
Essas são apenas algumas das possibilidades colocadas pelas funções gráficas do R, mas elas servem para demonstrar o quanto você pode conseguir de customização na visualização de dados e, quem sabe, estimular a curiosidade de vocês para se envolver mais com a linguagem.
Concluindo
Este primeiro contato com a linguagem R pode ter sido um pouco complicado e difícil, caso você não tenha familiaridade com programação, mas espero que ele tenha ajudado a quebrar o gelo e tornar os conceitos um pouco mais claros, bem como que tenha demonstrado algum potencial e interesse pela linguagem.
Copyright © 2020 Vinícius Maia. Nenhum Direito a menos.